
PDFファイルからテキストや数字を読み取るツール
複雑に組み込まれたPDFファイルから任意の数字やテキストを読み込みたい…。
AIで処理をつるために、複雑なPDFからシンプルなCSVを抽出したい。
そんな時の便利なツールがこの Tabula だ。
https://github.com/tabulapdf/tabula-java/releases
アプリをダウンロードすると、ローカルにPDFの読み込みの『import』 ボタンが発生する。
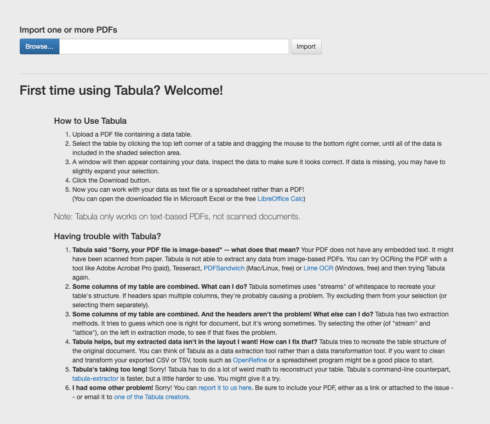
Tabula の使用方法
データ表を含むPDFファイルをアップロードする。
表の左上隅をクリックし、すべてのデータが網掛けの選択領域に含まれるまで、マウスを右下隅までドラッグして表を選択します。
すると、データを含むウィンドウが表示されます。データが正しいかどうか確認してください。データが欠けている場合は、選択範囲を少し広げる必要があるかもしれません。
ダウンロード・ボタンをクリックします。
これで、PDFではなくテキストファイルまたはスプレッドシートとしてデータを扱うことができます!
(ダウンロードしたファイルは、Microsoft Excelまたは無料のLibreOffice Calcで開くことができます。)
注:TabulaはテキストベースのPDFでのみ動作し、スキャンした文書では動作しません。
Tabulaには2つの抽出方法があります。Tabulaはどちらがドキュメントに適しているかを推測しようとしますが、時には間違っていることもあります。抽出モードの左側にある「stream」と「lattice」のうち、もう一方を選択してみて、問題が解決するかどうか試してみてください。
Tabulaはデータ変換ツールではなく、データ抽出ツールと考えることができます。エクスポートしたCSVやTSVをきれいに変換したいのであれば、OpenRefineのようなツールやスプレッドシートプログラムから始めるのがよいでしょう。
Tabulaは時間がかかりすぎる!申し訳ない!Tabulaはテーブルを再構築するために多くの奇妙な計算をしなければならない。Tabulaのコマンドライン版であるtabula-extractorの方が速いですが、少し使いにくいです。試してみるといい。
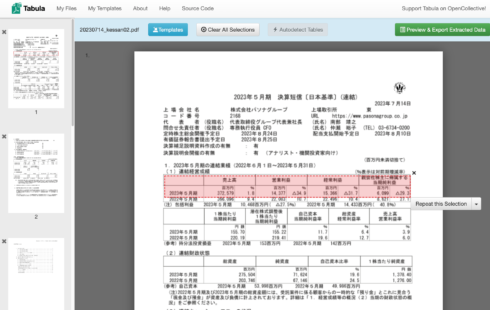
パソナグループの決算短信をダウンロードしてみました。
それを Tabulaで読み込み、範囲を選択する。
Preview&ExportExtacted Data をクリック
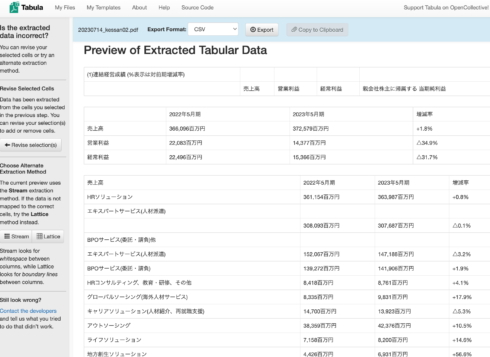
必要なところだけをSpreadSheetにコピペする。

CSVデータに書き出す前には、目視によるクリーニングが必要…。
参考…
https://www.bedroomcomputing.com/2020/11/2020-1114-tabula/
Views: 8

